


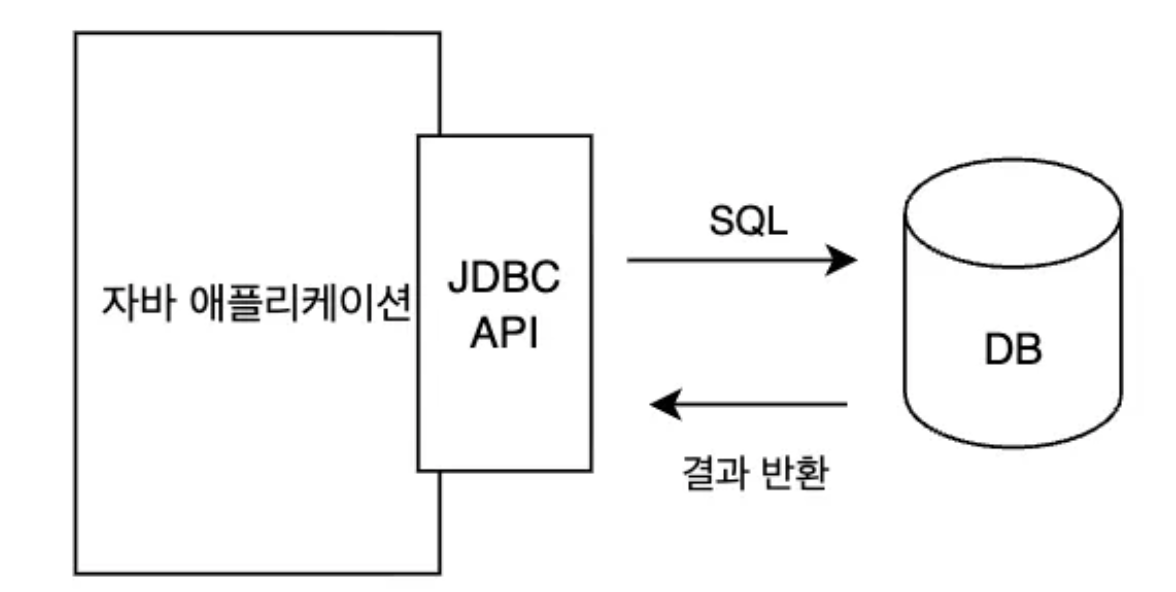
- JPA가 왜 필요한지 자바 애플리케이션 + JDBC API + DB(postgreSQL)를 만들어서 진행해보자
JDBC API를 직접 만들어서 문제점을 느껴보자
SQL를 다루어 불편한 점
DB 만들어보기
- pgAdmin 4 사용

Query Tool로 만들기
CREATE TABLE members (
id BIGSERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT NOW()
);
INSERT INTO members(name, email) VALUES
('JaeYoon', 'jaeyoon@example.com'),
('Test', 'test@example.com');
자바 프로젝트 만들기
- IntellJ 사용
Maven


<dependencies>
<!-- PostgreSQL JDBC Driver -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.3</version>
</dependency>
<!-- 테스트 (junit3 말고 최신으로 바꿔도 됨) -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.10.2</version>
<scope>test</scope>
</dependency>
</dependencies>
org.example에 DbConnectionTest를 만들자
package org.example;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class DbConnectionTest {
private static final String URL = "jdbc:postgresql://localhost:5432/jdbc_demo";
private static final String USER = "{본인 DB 사용자}";
private static final String PASSWORD = "{본인 비밀번호}";
public static void main(String[] args) {
// 1) 연결 테스트
try (Connection conn = DriverManager.getConnection(URL, USER, PASSWORD)) {
System.out.println("DB 연결 성공");
// 2) 간단 쿼리 테스트 (DB 버전 출력)
try (Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT version()")) {
if (rs.next()) {
System.out.println("DB Version: " + rs.getString(1));
}
}
} catch (Exception e) {
System.out.println("DB 연결 실패");
e.printStackTrace();
}
}
}
결과
DB 연결 성공
DB Version: PostgreSQL 16.4
Member 객체 생성
package org.example;
import java.time.LocalDateTime;
public class Member {
private Long id;
private String name;
private String email;
private LocalDateTime createdAt;
public Member() {}
public Member(Long id, String name, String email, LocalDateTime createdAt) {
this.id = id;
this.name = name;
this.email = email;
this.createdAt = createdAt;
}
public Member(String name, String email) {
this.name = name;
this.email = email;
}
public Long getId() { return id; }
public String getName() { return name; }
public String getEmail() { return email; }
public LocalDateTime getCreatedAt() { return createdAt; }
public void setId(Long id) { this.id = id; }
public void setName(String name) { this.name = name; }
public void setEmail(String email) { this.email = email; }
public void setCreatedAt(LocalDateTime createdAt) { this.createdAt = createdAt; }
@Override
public String toString() {
return "Member{" +
"id=" + id +
", name='" + name + '\\'' +
", email='" + email + '\\'' +
", createdAt=" + createdAt +
'}';
}
}
- 데이터베이스에 관리할 목적으로 회원용 DAO(데이터 접근 객체) 만들어보자
- find
- 조회용 SQL
- JDBC API를 사용해서 SQL 실행
- executeQuery
- 조회 결과를 map 함수를 이용해서 맵핑
public class MemberDAO {
public Optional<Member> findById(long id) {
String sql = """
SELECT id, name, email, created_at
FROM members
WHERE id = ?
""";
try (Connection conn = Db.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
// SQL 파라미터 바인딩
ps.setLong(1, id);
try (ResultSet rs = ps.executeQuery()) {
if (rs.next()) {
return Optional.of(map(rs));
}
return Optional.empty();
}
} catch (SQLException e) {
throw new RuntimeException("Member 조회 실패 (id=" + id + ")", e);
}
}
// ResultSet → Member 매핑
private Member map(ResultSet rs) throws SQLException {
Long id = rs.getLong("id");
String name = rs.getString("name");
String email = rs.getString("email");
Timestamp ts = rs.getTimestamp("created_at");
LocalDateTime createdAt = ts.toLocalDateTime();
return new Member(id, name, email, createdAt);
}
}
public class App {
public static void main(String[] args) {
MemberDAO dao = new MemberDAO();
dao.findById(1)
.ifPresentOrElse(
System.out::println,
() -> System.out.println("해당 ID의 회원이 없습니다.")
);
}
}
find만 만들었지만 벌써 머리 아프다..
SQL을 작성하고 JDBC API를 사용하는 비슷한 일을 반복해야할 것임.
그리고 Member 객체를 DB가 아닌 자바 컬렉션에 보관한다면 → list.add(member); 이렇게 객체를 저장할 수 있다.
근데 DB는 객체 구조와는 다른 데이터 중심의 구조를 가져서 DB에 직접 저장하거나 조회 불가능
그래서 문제는
- 맨날 개발자가 객체지향 애플리케이션과 DB 중간에서 SQL과 JDBC API를 사용해서 변환 작업을 직접 해주어야함.
- 객체를 DB에 CRUD 하려면 너무 많은 SQL과 JDBC API를 코드로 작성해야됨
또 다른 새로운 문제도 있다.
- 새로운 요구사항이 왔을 때 SQL과 JDBC API를 다 작성하고 조회를 실행해봤더니.. null이 나온다고 해보자 DB를 확인했을 때 새로운 요구사항에 맞게 데이터도 잘 들어감 알고보니 DAO에 추가된 메소드를 연결하지 않아 문제가 발생한 것 → DAO를 열고 어떤 SQL인지 알아야 원인 파악 가능
패러다임 불일치
- 객체 → 객체의 모든 속성 값을 꺼내서 파일이나 DB에 저장하면 됨 but 상속, 다른 객체 참조하고 있을 때 객체의 상태 저장하기 쉽지 않음
- 이 문제를 해결하기 위해 자바는 직렬화 기능을 지원함 but 직렬화된 객체를 검색하기 어려워서 현실성 없음
현실적인 대안 → 관계형 DB에 객체를 저장하는 것 → 이것도 불가능 DB는 데이터 중심으로 구조화, 객체지향의 추상화 상속, 다형성 같은 개념 없음
객체와 관계형 DB는 지향하는 목적이 서로 다르므로 둘의 기능과 표현 방법도 다름 → 객체와 관계형 DB의 패러다임 불일치 문제 그래서 객체 구조를 테이블 구조에 저장하는 데는 한계가 있다.
패러다임 불일치로 인해 어떤 문제점이 정확하게 있을까?
- 객체는 상속이라는 기능을 가지고 있지만 테이블은 상속이라는 기능이 없다.
- DB 모델링에서 슈퍼타입 서브 타입을 사용하며 객체 상속과 가장 유사한 형태로 테이블을 설계 가능 == 부모 테이블에 DTYPE(예시)이라는 컬럼를 주고 자식들 → JDBC API로 하면 정말 어마어마하게 SQL 작성..
- 조회하다고 해도 join 엄청 많음
- 개발자가 중간 변환 역할을 해야함
- 객체는 참조를 사용해서 다른 객체와의 연관관계를 맺으며 참조에 접근해서 연관된 객체를 조회 but 테이블은 외래키 사용
- 객체의 연관관계는 Member → Team 일 때 Member.getTeam()으로 진행
- Member 테이블은 MEMBER.TEAM_ID 외래키를 가지고 관계를 맺음
- 객체는 참조가 있는 방향으로만 조회 가능
- Member.getTeam()은 가능하지만 team.getMember()는 불가능
- DB는 이게 가능
- 저장 → 객체를 DB에 저장하려면 team 필드를 TEAM_ID 외래 키 값으로 변환해야함
- Member.getTeam().getId();
- 조회 → TEAM_ID 외래 키 값을 Member 객체의 team 참조로 변환해서 객체에 보관해야함.
- 객체는 참조를 사용해서 다른 객체와의 연관관계를 맺으며 참조에 접근해서 연관된 객체를 조회 but 테이블은 외래키 사용
2번 코드를 직접 해보자 → 지금 위 코드까지 했으면 member만 있음
CREATE TABLE teams (
id BIGSERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL
);
ALTER TABLE members
ADD COLUMN team_id BIGINT;
ALTER TABLE members
ADD CONSTRAINT fk_members_team
FOREIGN KEY (team_id)
REFERENCES teams(id);
Team 클래스
package org.example;
public class Team {
private final Long id;
private final String name;
public Team(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() { return id; }
public String getName() { return name; }
@Override
public String toString() {
return "Team{id=" + id + ", name='" + name + "'}";
}
}
TeamDAO
package org.example;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class TeamDAO {
public Team findById(long id) {
String sql = "SELECT id, name FROM teams WHERE id = ?";
try (Connection conn = Db.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setLong(1, id);
try (ResultSet rs = ps.executeQuery()) {
if (rs.next()) {
return new Team(
rs.getLong("id"),
rs.getString("name")
);
}
return null;
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
MemberDAO
package org.example;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Optional;
public class MemberDAO {
private final TeamDAO teamDAO = new TeamDAO();
public Optional<Member> findById(long memberId) {
String sql = """
SELECT id, name, team_id
FROM members
WHERE id = ?
""";
try (Connection conn = Db.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setLong(1, memberId);
try (ResultSet rs = ps.executeQuery()) {
if (!rs.next()) {
return Optional.empty();
}
Long id = rs.getLong("id");
String name = rs.getString("name");
Long teamId = rs.getLong("team_id");
// 개발자가 직접 연관관계 설정
Team team = teamDAO.findById(teamId);
Member member = new Member(id, name, team);
return Optional.of(member);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
코드에서 개발자가 직접 연관관계를 다음과 같은 코드로 직접 연결
Team team = teamDAO.findById(teamId);
Member member = new Member(id, name, team);
3. 객체 그래프 탐색
Team tea = member.getTeam();
- 객체는 마음껏 객체 그래프 탐색을 할 수 있어야함. but member 객체를 조회할 때 SQL에서 team을 같이 조회하지 않으면 객체 그래프 탐색 불가능
4. 비교
- DB에는 기본 키의 값으로 각 로우를 구분 반면 객체는 동일성(identity) 비교와 동등성(equality) 비교가 있음
- 동일성 비교는 == 비교. 객체 인스턴스의 주소 값 비교
- 동등성 비교는 equals() 메소드를 사용해서 객체 내부의 값을 비교
- 객체 측면에서 같은 Member DB에서 조회했지만 객체 인스턴스 입장에서는 이게 다른 거
JPA 이런 문제들을 어떻게 해결?
- JPA가 제공하는 API를 사용해서 간편하게 CRUD 작성 가능
- 패러다임 불일치인 상속 관계를 JPA가 해결해줌
- JPA는 부모와 자식 두 테이블을 조인해서 필요한 데이터를 조회하고 그 결과를 반환
- 패러다임 불일치인 문제를 JPA는 연관관계를 해결줌
- member.setTeam(team); jpa.persist(member); 이걸 통해 JPA는 team의 참조를 외래 키로 변환해서 적절한 INSERT SQL을 DB에 전달
- JPA는 연관된 객체를 사용하는 시점에 적절한 SELECT SQL을 실행함 그래서 객체 그래프 탐색을 맘껏 할 수 있음 또한 실제 객체를 사용하는 시점까지 DB 조회를 미루는 개념인 지연 로딩을 지원해줌
- JPA는 같은 트랜잭션일 때 같은 객체가 조회되는 것을 보장
JPA란 무엇인가?
- JPA(Java Persistence API)는 자바 진영의 ORM 기술 표준
- ORM(Object-Relational Mapping)은 이름 그대로 객체와 관계형 DB를 매핑한다는 뜻 → ORM 프레임워크는 객체 와 테이블을 매핑해서 패러다임의 불일치 문제를 개발자 대신 해줌
다음 사진과 같이 저장할 때 조회할 때 ORM 프레임워크가 대신 해줌

- 자바 진영에서 다양한 ORM 프레임워크들이 있는데 그 중 하이버네이트 프레임워크가 가장 많이 사용됨
- JPA는 자바 ORM 기술에 대한 API 표준 명세임.
- JPA를 사용하려면 JPA를 구현한 ORM 프레임워크를 선택해야함.

JPA를 왜 사용해야할까?
- 생산성 → JPA를 사용하면 JDBC API를 사용하는 지루하고 반복적인 일은 JPA가 대신 처리해줌 지루한 CRUD용 코드와 SQL을 직접 작성하지 않아도 됨
- 유지보수 → 개발자가 작성해야했던 SQL과 JDBC API 코드를 JPA가 대신 처리해주어 유지보수를 해야하는 코드 수 줄어든다.
- 패러다임 불일치 해결 → JPA는 상속, 연관관계, 객체 그래프 탐색, 비교하기 같은 거 다 해결
- 성능 → JPA는 애플리케이션과 데이터베이스 사이에서 다양한 성능 최적화 기회 제공
- 데이터 접근 추상화 벤더 독립성 → RDBMS는 같은 기능도 벤더마다 사용법이 다름 이걸 자동으로 다 해결해줌
JPA는 자바 진영의 ORM 기술 표준!!
코드 레포지토리
'개발 지식 > Spring boot' 카테고리의 다른 글
| [Spring boot] JPA - Spring data JPA가 아닌 순수 JPA (0) | 2026.01.30 |
|---|---|
| [Spring boot] Maven VS Gradle (0) | 2026.01.22 |
| [Spring boot] 카카오 로그인 Oauth 2.0 (0) | 2025.01.05 |
| [Spring boot] 폴더 구조 (2) | 2025.01.05 |
| [Spring boot] Logger 설정 (0) | 2025.01.05 |