계산 프로세스 - 컴퓨터 속에 있는 것이며, 데이터라고 하는 것을 조작하면서 어떤 일을 한다.
프로세스 - 사람이 만든 규칙에 따라 움직이고
프로그램 - 위 규칙을 가리켜 프로그램이라고 한다.
프로그램을 통해 우리의 주문대로 컴퓨터의 혼을 만들어낸다.
계산 프로세스란, 마법사가 넋을 불러내려 할 때 머릿속에 떠올리는 생각과 엇 비슷하여, 보거나 만지지는 못하지만 없다고 무시할 수 없는 그 무엇이다. 프로세스는 사람 대신 머리 쓰는 일을 하고 질문에 답하기도 하고 은행에서 돈을 찾거나 공장에서 로봇 파을 움직여 물건을 만들어 내기도 하는데, 이런 식으로 우리 세상살이에 영향을 준다. 프로세스를 다스리는 프로그램은 마치 넋을 다스리는 마법사의 주문과 같다고 볼 수 있다.
프로그램은 조심스럽게 써내려간 여러 식으로 이루어진다. 이런 식을 적을 때 쓰는 말을 프로그래밍 언어라 한다.
정리
-계산 프로세스 > 프로세스 > 프로그램 > 프로그래밍 언어
프로그래밍 언어란?
-프로세스가 할 일을 적기 위해 만든, 신비롭고 비밀스런 마법과 같다. 컴퓨터가 고장나지 않았다면, 프로세스는 프로그램에서 정한 대로 일을 해내게 되어 있다. 그러므로 초보 프로그래머는 견습 마법사가 그리 하는 것처럼, 자기가 부린 마법이 어떤 결과를 일으킬지 미리 알아차리는 방법을 배워야한다.
프로그램을 짤 때 조심해야한다. 진짜로 일하는 데 쓸 프로그램은 깊은 지식과 경험을 갖춘 사람이 조심해서 짜야 한다. CAD(Computer-Aided Design Program)프로그램 속에 있는 작은 오류 하나가, 그 프로그램으로 설계한 비행기를 곤두박질치게 하거나 댐을 무너져 내리게 하고 산업 로봇을 망가뜨리는 엄청난 사고로 이어질 가능성이 얼마든지 있다.
그러므로 소프트웨어 기술자라면 스스로 만든 프로세스가 맡은 일을 틀림없이 해낸다고 믿을 수 있도록 제대로 프로그램을 짤 줄 알아야 한다. 자기가 설계한 시스템이 앞으로 어떻게 움직일지 정확하게 그려낼 수 있어야 하고, 생각지도 못한 문제 때문에 끔찍한 사고가 터지지 않게끔 프로그램의 얼개(구조)를 제대로 잡을 줄 알아야 전문가라고 할 수 있다.
Lisp로 프로그램을 짠다는 것
프로세스를 나타내기 위해 알맞은 표현 수단이 있어야한다. 이 책에서는 Lisp 프로그래밍 언어 선택.
우리가 보통, 생각을 글로 옮겨 적을 때 한글이나 영어 같은 자연어(natural language)를 쓰고, 셈하는 방법을 적을 대 수식을 쓰는 것처럼, 컴퓨터 프로세스를 나타낼 때에는 Lisp 같은 프로그래밍 언어를 쓴다. Lisp는 수학에서 쓰는 논리식 같운데 재귀 방정식을 컴퓨터 계산 모형으로 사용할 수 있는지 엄밀히 살펴보기 위해 존 매카사가 만든 언어다
이것은 쓰는 사람의 바람에 맞추어 새로운 기능을 넣기도 하고, 여러 가지 언어 기능을 쓸모 있게 만드는 방법을 연구하는 가운데 오랫동안 수많은 실험을 거치면서 자라난 언어다.
왜 이 언어를 사용하여 프로그램 짜는 법을 가르치려 드는 것일까?
-Lisp 언어만이 갖춘 여러 특징이 있다. 다시 말해, 프로그램을 짜는 데 필요한 여러 원소와 갖가지 데이터 구조를 공부하고, 이를 뒷받침하는 데 어떤 언어 기능이 있어야 하는지를 관계지어 설명하기에 Lisp는 여러 모로 알맞은 점이 많다. 그 가운데에서도 프로시저를 보통 데이터처럼 쓸 수 있다는 것이 가장 두드러진 점이다. 왜냐하면 '열심히 일하는'데 프로세스가 '가만히 있는' 데이터를 쓴다는 흔한 생각과 달리, 데이터와 프로시저를 엄격하게 구분 짓지 않는 데 바탕을 두는 쓸모 있는 프로그램 설계 기술이 여럿 있기 때문이다. 그 기술을 탐구하는 데 Lisp가 가장 편리한 수단이 될 텐데, 그 까닭은 프로시저를 데이터처럼 다루는 Lisp의 유연성에서 찾을 수 있다. 또한 똑같은 까닭에서 Lisp는 컴퓨터 언어를 처리하는 실행기나 번역기 같이 다른 프로그램을 데이터처럼 받아서 처리하는 프로그램을 짜는 일에 쓰기에도 아주 좋은 언어다.
좋은 프로그래밍 언어
-프로그래밍 언어는 프로세스에 대한 사람의 생각을 짜임새 있게 담아내는 그릇이기도 하다. 그러므로 언어를 설명할 때에는 다른 무엇보다 단순한 생각을 모아 복잡한 생각을 엮어내는 수단에 무게를 두어야 한다. 좋은 프로그래밍 언어라면 세 가지 표햔 방식을 갖추고 있다.
1. 기본 식 - 언어에서 가장 단순한 것을 나타낸다.
2. 엮어내는 수단 - 간단한 것을 모아 복잡한 것으로 만든다.
3. 요약하는 수단 - 복잡한 것에 이름을 붙여 하나로 다룰 수 있게끔 간추린다.
프로그램을 짤 때 우리는 프로시저와 데이터라는 두 가지를 쓴다.
데이터란 프로시저에서 쓰려는 물건, 프로시저란 데이터를 처리하는 규칙
좋은 프로그래밍 언어에는 기본 데이터와 기본 프로시저를 나타내고, 프로시저들과 데이터를 엮어서 더 복잡한 것을 만들고, 이를 간단하게 요약하는 수단이 반드시 있어야 한다.
이 장에서는 숫자 데이터를 가볍게 다루면서 프로시저 짜는 방법에 초점을 둔다.
1.1.1 식
우리가 식을 쳐 넣으면, 실행기는 그 식을 셈하여 값을 찍는다.
수를 나타내는 식은 실행기가 곧바로 셈할 수 있는 기본 식이다. (정확히 말하면, 십진수 숫자로 나타낸 식을 적는다고 해야 맞다.)


+, * 기호들이 프로시저가 되고 이것을 이용하여 프로시저에 수를 넘겨서 그 값을 계산하겠다는 말
리스트를 만들고 프로시저 적용을 뜻하도록 엮어 놓은 식은 엮은식이라고 한다.
이 리스트에서 맨 왼쪽에 있는 식(기호)는 연산자가 되고 나머지는 피연산자가 된다.
엮은식을 계산한 값은, (피연산자의 값이 되는) 인자에 (연산자가 나타내는) 프로시저를 적용하여 얻는다.
연산자를 피연산자 왼쪽에 두는 방식을 앞가지 쓰기라고 한다.
복잡한 식을 이렇게 정리하면 사람도 알아보기 쉽다. 이와 같이 식을 깊이 겹쳐 써야 할 때 인자를 중심으로 줄을 맞추고 알맞게 들여쓰는 방식을 가지런히 쓰기라고 한다. 식이 제아무리 복잡해도, 실행기가 하는 일은 언제나 같다. 식을 읽어 들이고 값을 구한 다음에 그 값을 찍는다. 이를 가리켜 보통, 읽고 셈하고 찍는 일을 되풀이 한다고 한다.
1.1.2 이름과 환경
프로그래밍 언어에서 아주 중요한 기능 가운데 하나는 계산 물체에 이름을 붙이는 수단이다. 이때 이름은 변수가 되고, 그 변수의 값은 계산 물체가 된다.

define은 Scheme에서 합친 연산을 간추리는 수단으로 이 기능을 쓰면 복잡한 식을 계산한 값에 알기 쉬운 이름을 붙여 쓸 수도 있다.

어떤 값에 이름을 붙여 두었다가 뒤에 그 이름으로 필요한 값을 찾아 쓸 수 있다는 말은, 실행기 속 어딘가에 이름-물체의 쌍을 저장해 둔 메모리가 있다는 뜻이다. 이런 기억 공간을 환경이라고 한다.(여기서 환경이란 맨 바깥쪽에 있는 바탕 환경을 말한다.)
1.1.3 엮은식을 계산하는 방법
어떤 일을 제대로 하려면, 큰 일을 작은 일로 알맞게 나눈 다음에 작은 일을 어떤 차례로 해내갈지 정해야 한다. 이렇게 절차대로 일하는 방법으로 짤 때 짚어 볼 문젯거리가 몇 개 있는데, 그런 얘기만 따로 모아 다루는 것이 이 장의 목적 가운데 하나다. 우선 엮은식의 값을 계산하는 차례가 다음과 같다고 하자.
1. 엮은식에서 부분 식의 값을 모두 구한다.
2. 엮은식에서 맨 왼쪽에 있는 식(연산자)의 값은 프로시저가 되고, 나머지 식(피연산자)의 값은 인자가 된다. 프로시저를 인자에 적용하여 엮은식의 값을 구한다.
이 규칙의 첫 단계를 살펴보면, 엮은식의 값을 셈하는 프로세스를 끝내려면 부분 식부터 계산해야 하는데, 부분 식의 값을 셈할 때에도 똑같은 프로세스를 따르도록 하고 있다. 한 마디로, 이 계산 규칙은 자연스레 처음으로 되도는 프로세스다. 다시 말해, 어떤 규칙의 한 단계에서 똑같은 규칙을 다시 밟도록 해놓았다는 말이다.

나무 그림속에서 연산자는 마디로, 연산할 것들은 가지로 나타내며, 끝 마디에는 연산자나 수가 달려있다. 계산 프로세스를 나무에 빗대여 설명해 보면, 피연산자의 값들이 끝 마디부터 가지를 타고 하나씩 더 높은 단계로 올라가며 엮이는 셈이다. 보통 이렇게 같은 절차를 여러 번 되밟는 기법, 줄여서 되돌기는 나무 같은 계층 구조 물체(데이터)를 다루기에 알맞은 기법이다. 사실 이렇게 '값을 위로 올려 보내는' 규칙은 나무꼴 어큐물레이션이라 하는 더 일반적인 계산 방법의 한 가지다.


그냥 (+ x 1)이 있다면 전혀 계산하지 못한다. 그래서 보통 계산 규칙으로는 값을 구하지 못하기 때문에 계산 규칙이 따로 밝혀져 있어야 하는 문법을 특별한 형태라고 한다. 지금까지 나온 특별한 형태는 define뿐이지만, 곧 다른 것도 볼 수 있다. 이렇게 여러 종류의 식이 모여서 프로그래밍 언어의 문법을 이루게 된다.
1.1.4 묶음 프로시저
프로시저를 어떻게 정의 하는지 배울 차례.
프로시저 정의란 복잡한 연산에 이름을 붙여서 쓰는 방법으로, 큰 프로그램을 짤 적에 아주 쓸모가 많다.


이미 있던 다른 프로시저를 하나로 묶어서 만든 프로시저, 곧 square라 이름 붙인 묶음 프로시저 하나가 새로 생긴다. 곱할 값을 x라는 갇힌 이름(local name)으로 받아 오는데. 이는 마치 자연어에서 대명사와 씀이새가 비슷하다. 이 프로시저가 정의를 계산한 결과로, 새로운 묶음 프로시저가 하나 생기는데, 그 이름을 square라고 지은 것이다.

<name>은 환경에서 프로시저를 가리키는 이름이다. <formal parameters>는 프로시저가 받아오는 인자를 가리키기 위해서 프로시저의 몸 속에서 쓰는 이름이다. <body>는 프로시저를 불러 쓸 때마다 계산할 식을 말하는 데, 프로시저에 인자를 건네면 몸 식 속에 있는 인자 이름을 인자 값으로 맞바꾼 다음에, 그 식의 값을 구하게 된다.
1.1.5 맞바꿈 계산법으로 프로시저를 실행하는 방법
모든 부분 식의 값을 구한 다음에, 연산자의 값으로 나온 프로시저를 연산할 값, 곧 인자에 맞추어 계산하면 된다. 기본 프로시저를 계산하는 방법은 이미 실행기 속에 정해져 있다고 보고, 새로 만들어 쓰는 묶음 프로시저의 맞춤은 다음 규칙에 따라 계산할 수 있다.
묶음 프로시저를 인자에 맞춘다는 것은, 프로시저의 몸 속에 있는 모든 인자 이름을 저마다 그에 대응하는 인자 값으로 맞바꾼 다음, 그렇게 얻어낸 식의 값을 구하는 것이다.
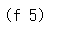






설명
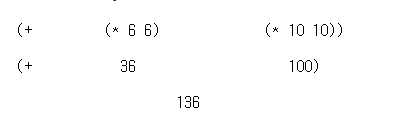
f를 구하기 위해 a에 5를 대입한다. 연산자의 값을 구하여 프로시저를 얻어야 하고, 나머지 두 식(피연산자)의 값을 구하여 인자 값으로 삼아야 한다. 그리하면 6과 10이 되니까, 다시 6과 10이라는 인자에 sum-of-squares를 맞추어야 한다. sum-of-squares의 몸에서 인자 이름 x와 y는 인자 값 6과 10에 대응하므로 이를 서로 맞바꾸고 나면 3번째 그림이 되는 것이다. 이런 프로세스(과정)에 따라, 프로시저를 맞추는 방법을 맞바꿈 계산법이라고 한다. 이 방법은, 적어도 이 장에서 정의하는 프로시저에 대해서는 프로시저를 인자에 맞춘다는 게 무슨 뜻인지 밝힌 것이라 볼 수 있다.
하지만 꼭 알아야 할 두 가지가 있다.
1. 이해하는 데 도움을 주려고 한 것 뿐, 실행기가 정말 그렇게 돌아간다는 뜻이 아니다.
2. 점점 더 정교한 계산법, 곧 실행기가 어떻게 돌아가는지 차례로 보여주다가 5장에서 완전한 실행기와 번역기를 보여준다.
인자 먼저 계산법과 정의대로 계산법
값이 필요할 때까지 피연산자들을 계산하지 않고 미루어 두는 방법도 있다 다시 말해, 인자 값을 계산하지 않고 식 자체를 인자 이름과 맞바꾸어 가다가 마지막에 기본 연산으로만 이루어진 식, 즉 더 펼치지 못하는 식을 얻을 때 그 식의 값을 구하는 방법이 있다.


앞서 본 것과 다르지 않지만, 계산 프로세스가 다르다. 특히 3번째 줄을 바꾼 것 이와 같이 '끝까지 펼친 다음에 줄이는' 계산 방법을 정의한 대로 계산하는 방법이라고 하고, '인자 값부터 먼저 구하는' 방법을 인자 값 먼저 계산하는 법이라고 한다. 실제로 Lisp 실행기는 인자 먼저 계산법을 쓴다.
1.1.6 조건 식과 술어
조건에 따라서 연산하는 방법을 고르는 표현 수단이 없었기 때문에, 프로시저로 나타낼 수 있는 일이 그렇게 폭넓지 않았다.

그래서 위 그림처럼 양수인지 음수인지 0인지 따져보고 절대값을 달리 계산하는 규칙이 있을 때, 이런 생각을 프로시저로 표현할 방법이 없었다. 위와 같이 하는 것을 갈래 나누기라 하는데 Lisp에는 이를 나타내는 문법(특별한 형태)이 따로 있다. 그 문법의 이름은 (conditional 이라는 낱말에서 따온) cond이다.
cond


cond라는 이름 뒤에는 두 식을 괄호로 묶어 놓은 p, e 곧 절이 여러 개온다. 절을 이루는 두 식 가운데 첫 식을 술어라 하는데, 그 답은 언제나 참 또는 거짓 가운데 하나를 내놓는다.
술어는 참이나 거짓이라고 대답하는 프로시저 또는 식을 가리킬 때 널리 쓰는 말이다.
abs
절대값 프로시저 abs의 몸 속에서는 기본 술어 프로시저 >, <, =를 쓰고 있다. 이 술어들은 두 수를 인자로 받아서 앞 수가 뒤 수보다 크거나 작거나 같은지 따져보고 참이나 거짓이라고 답을 내놓는 기본 프로시저다.

if

실행기는 <predicate>을 먼저 계산하고 그 답이 참이라면 <consequent>, 아니면 <alternative>의 값을 구하여 if 식의 값으로 내놓는다. <,>,= 와 같은 기본 술어 말고도 복잡한 논리나 판단을 나타낼 수 있게끔 논리 식을 묶는 연산도 있다.

식 e를 왼쪽에서 오른쪽으로 계산. 거짓이라 대답하는 e가 나오면 and 식의 값은 거짓이 되고, 나머지 e의 값을 구하지 않는다. 모든 e가 참일 때에는 마지막 식의 값을 and 식의 값으로 내놓는다.

식 e를 왼쪽에서 오른쪽으로 계산. 참이라 대답하는 e가 나오면 or 식의 값은 참이 되고, 나머지 e의 값은 구하지 않는다. 모든 e가 거짓일 때에는 마지막 식의 값을 or 식의 값으로 돌려준다.

e가 참이면 not 시그이 값으로 거짓을, 거짓이면 참을 내놓는다.
1.1.7 연습: 뉴튼 법으로 제곱근 찾기
얻고자 하는 값에 가까운 값을 차례로 되풀이 해서 구해 나가는 뉴튼 법
x의 제곱근에 가까운 값 y가 있을 때 y와 x / y 의 평균을 구하여 진짜 제곱근에 더 가까운 값을 구하는 방법이다.
2의 제곱은을 구해보자. 가까운 값 1






1.1.8 블랙박스처럼 간추린 프로시저
square 프로시저가 어떻게 값을 구하는지는 몰라도 제곱한 값을 내놓는다는 것을 알 수 있다. square는 프로시저라기보다 프로시저를 묶어서 간추려 놓은 이름일 뿐이다. 이것을 프로시저 요약하기라고 한다. 프로시저를 불러 쓰는 쪽에서는 어떤 프로시저를 쓰더라도 제곱한 값을 얻기만 하면 된다.

프로시저를 쓰는 사람이 필요한 프로시저를 하나하나 만들어 쓰지 않고, 다른 사람이 만든 것을 블랙박스처럼 불러 쓸 수 있다. 프로시저를 쓰는 사람은 그것이 무슨 일을 하는지만 알면 되지, 굳이 그것을 어떻게 만들었는지는 몰라도 된다.
갇힌 이름
프로시저를 만드는 쪽에서는 그것을 쓰는 쪽에 어떤 영향도 줘서는 안 되는데, 그 가운데 하나가 프로시저를 정의할 때 쓰는 인자 이름이다.

쉽게 말해서 프로시저의 매개변수 이름이 프로시저가 뜻하는 바에는 아무런 영향을 주지 않아야 한다는 원칙
결국 프로시저 정의에서 쓰는 매개변수 이름은 프로시저에 갇힌, 곧 몸 속에서만 쓰는 이름이어야 한다.
안쪽 정의와 블록 구조
지금까지는 인자 이름이 프로시저에 매인 것을 보기로 들어 이름 가둬놓기를 설명하였다. 이번에는 제곱근 프로그램에서 이름 가둬놓기의 다른 쓰임새를 찾아보자.

이 프로시저를 쓰는 쪽은 sqrt만 있으면 된다. 다른 프로시저(sqrt-iter, good-enought?, improve)는 sqrt의 쓰임새를 헷갈리게 만들 뿐이다. 또한 다른 프로그램에서 good-enough?라는 프로시저를 만들어 쓰고 싶을 때 그렇게 못한다. sqrt에서 이미 그 이름을 쓰기 때문이다. 결론적으로 good-enough? 같은 프로시저를 다른 프로그램과 얽히지 않게 하려면 이런 프로시저를 sqrt 속에 숨길 수 있어야 한다.

위 그림처럼 하면 된다. 이렇게 프로시저 정의를 겹쳐 쓰는 모양을 블록 구조라고 한다.
이 정의는 x가 sqrt에 매이기 때문에, 이제는 프로시저 마다 따로따로 x를 인자로 건네줄 필요가 없다. 다시 말해 x를 프로시저마다 매어 놓지 않고 자유 변수로 만들어도 된다. 이때 x는 sqrt가 받아 온 인자다. 이를 두고 문법에 따라(변수가 보이는) 넓이가 정해지는 규칙을 따른다고 한다.

'컴퓨터 프로그램의 구조와 해석 > 1장 프로시저를 써서 요약하는 방법' 카테고리의 다른 글
| 1.3 차수 높은 프로시저로 요약하는 방법 (0) | 2022.02.02 |
|---|---|
| 1.2 프로시저와 프로세스 (0) | 2022.01.31 |