큐는 입력과 출력 창구가 따로 존재하고, 제일 먼저 들어간 데이터가 제일 먼저 나오는 자료구조이다.
근데 입력한 순서대로 데이터를 처리할 것 같으면 왜 큐를 사용할까?
:데이터 입력이 폭주하는 경우를 생각해보자. 먼저 입력받은 데이터의 처리가 안 끝났는데 그 뒤에 새로운 데이터가 마구 입력되면 그 데이터들은 보관할 장소가 따로 없으므로 모두 버려야한다. 이럴 때 밀려드는 데이터를 '보관할 '장소로 큐가 필요하다.
먼저 들어가고 먼저 나오는(FIFO(First In First Out)), 또는 선입선출 자료구조를 큐라고 한다.
큐는 우리 말로 번역하면 대기행렬이라고 하는데, 대기가 기다리다. 행렬이 줄이라는 뜻이니 큐는 '기다리는 줄'이라고 할 수 있다.
큐의 주요 기능: 삽입과 제거
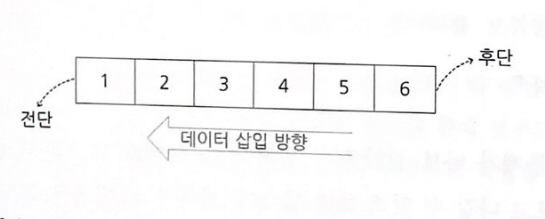
큐의 가장 앞 요소를 전단(Front). 그리고 가장 마지막 요소를 가리켜 후단(Rear)이라고 부른다. 큐는 삽입은 후단, 제거는 전단에서 각각 수행된다.
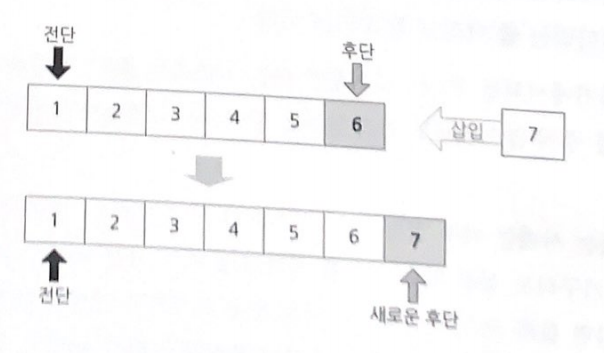
삽입은 후단에 노드를 덧붙여서 새로운 후단을 만드는 연산이다.
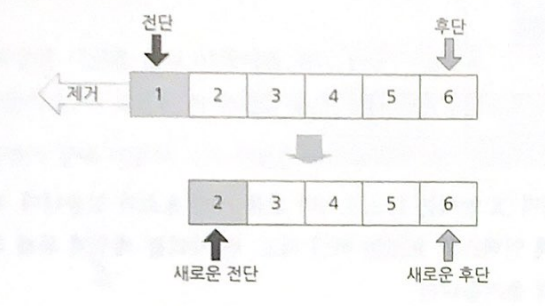
제거는 전단의 노드를 없애서 전단 뒤에 있는 노드를 새로운 전단으로 만드는 연산이다.
순환 큐
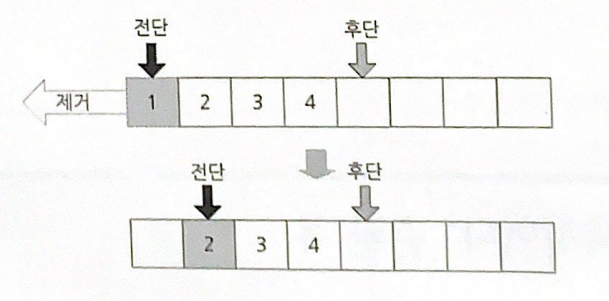
큐를 배열로 구현해야 한다면 어떻게 구할까? 우선 제거 연산만 생각해보자
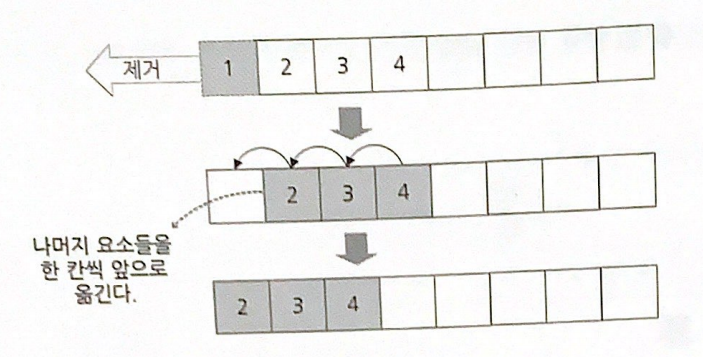
이 그림의 큐 배열의 크기는 8이며 그 안에는 1, 2, 3, 4의 값을 가진 요소가 있다. 전단인 1을 제거하면 배열 내에 첫 번째 인덱스의 요소는 비게 되고, 빈 자리를 채우기 위해 뒤에 있던 2, 3, 4 요소가 앞으로 한 칸씩 옮겨온다.
문제점
그런데 이 방식의 문제점이 있다. 전단을 제거한 후 나머지 요소를 한 칸씩 앞으로 옮기는데 드는 비용이다.
해결 방법
전단을 가리키는 변수를 도입해서, 배열 내의 요소를 옮기는 대신 변경된 전단의 위치만 관리하는 것이다. 이와 함께, 후단을 가리키는 변수도 도입해서 삽입이 일어날 때마다 변경되는 후단의 위치를 관리한다. 후단을 가리키는 변수에 실제 후단의 위치보다 1을 더한 값을 가진다.
이렇게 하면 배열 요소들의 이동으로 인한 부하 문제는 해결할 수 있다. 그런데 여기서 새로운 문제가 발생한다.
문제점2
제거 연산을 수행할수록 큐의 가용 용량도 줄어들기 때문이다.
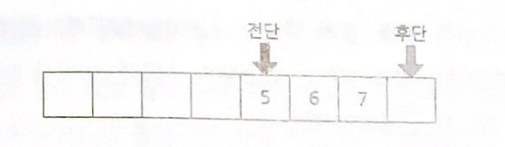
그림에서 큐는 초기 용량이 8개 였지만, 제거 연산을 4차례 수행해서 용량이 반밖에 남지 않았다. 게다가 후단도 배열의 끝을 도달해 있다.
해결 방법
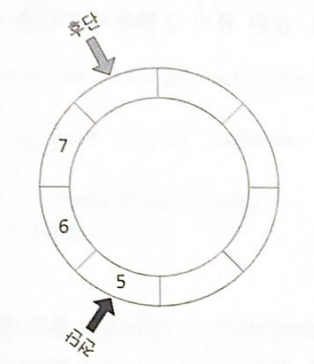
배열의 끝과 시작이 연결했다고 가정하고 삽입을 해보자
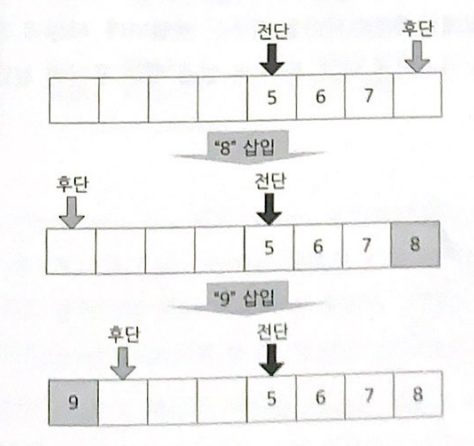
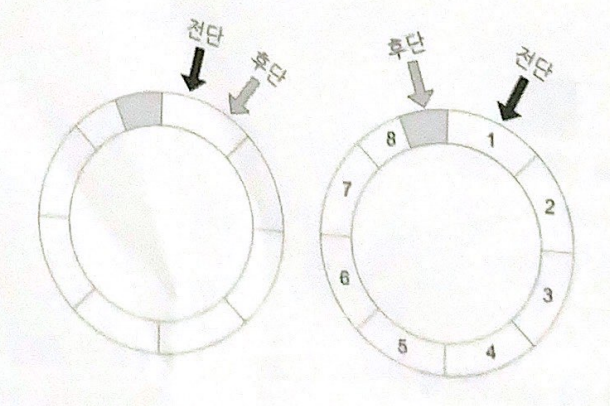
배열의 마지막 요소가 후단이었을 때 8을 삽입하면서 배열의 첫 번째 요소가 후단이 되었다. 여기에 또 9를 삽입하면서 두 번째 요소가 후단이 되었다. 삽입이 이루어질 때마다 후단이 뒤로 후퇴하다가 전단을 만나게 되면 그 큐는 비로소 '가득 찬 상태'가 된다. 이 경우에는 뭔가를 큐에 더 밀어 놓고 싶어도 할 수가 없게 되는 것이다.
이렇게 시작과 끝을 연결해서 순환하도록 고안된 큐를 '순환 큐'라고 한다.
비어 있거나 또는 가득 차 있거나
그런데 순환 큐도 문제가 있다. 순환 큐는 비어 있는 상태와 가득 차 있는 상태를 구분할 수 없다. 순환 큐의 구현에서 후단은 실제의 후단에 1을 더한 값을 가짐을 기억하자(변수).
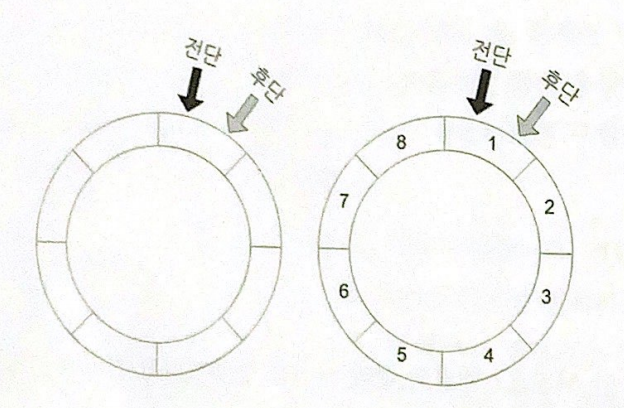
이 문제를 해결하기 위해서 일반적인 해법은 큐 배열을 생성할 때 실제의 용량보다 1만큼 더 크게 만들어서 전단과 후단(실제 후단) 사이를 비우는 것이다. 이렇게 하면 큐가 비어 있을 때 전ㄷ나과 후단이 같은 곳을 가리키게 되고, 큐가 차 있을 때는 후단이 전단 보다 1 작은 값을 갖게 된다.
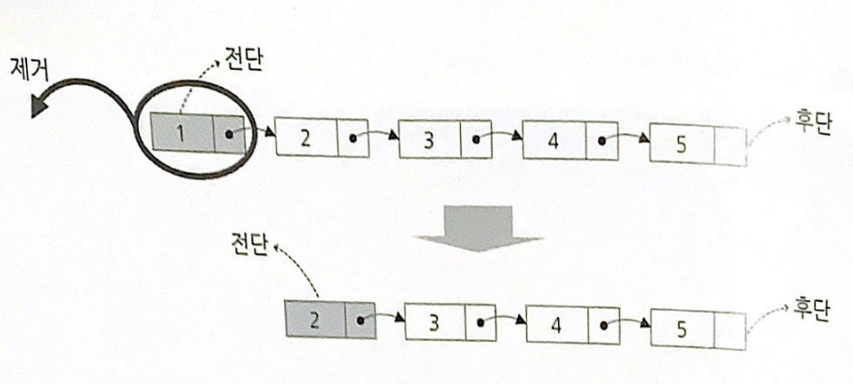
링크드 큐
링크드 큐의 각 노드는 앞 노드에 대한 포인터를 이용해 구성되어 있기 때문에, 삽입은 새 노드의 포인터에 후단을 연결하고 제거는 진단 바로 이후의 노드에서 전단에 대한 포인터를 거두어 들이는 것으로 구현이 끝난다.
'Algorithm > 뇌를 자극하는 알고리즘' 카테고리의 다른 글
| 5장 정렬 (0) | 2022.02.14 |
|---|---|
| 4장 트리 (1) | 2022.02.02 |
| 2장 스택 (0) | 2022.02.01 |